
|
Getting your Trinity Audio player ready...
|
Large language models (LLMs) are not built overnight—they undergo a structured, multiphase development process that transforms them from raw data processors into highly sophisticated AI systems capable of understanding and generating human-like text.
This process involves three key phases, each playing a crucial role in shaping the model’s linguistic abilities, contextual understanding, and responsiveness to real-world interactions.
1. Pre-training: Learning from Massive Data
This is the foundation stage, where the model is trained on vast amounts of text data from diverse sources, such as books, websites, academic papers, and code repositories. The goal is for the model to learn:
- Grammar and Syntax: Understanding sentence structures, punctuation, and linguistic rules.
- World Knowledge: Absorbing factual information about history, science, technology, and common sense reasoning.
- Patterns and Relationships: Recognizing word associations, contextual meaning, and even programming logic.
At this stage, the model doesn’t have a deep understanding of meaning or intent—it simply predicts the next word based on probabilities learnt from the data. This is why raw pre-trained models can sometimes generate biased or nonsensical outputs.
2. Fine-tuning: Customizing for Specific Use Cases
Once pre-training is complete, the model undergoes fine-tuning using carefully curated datasets to enhance performance, reduce biases, and align responses with human values.
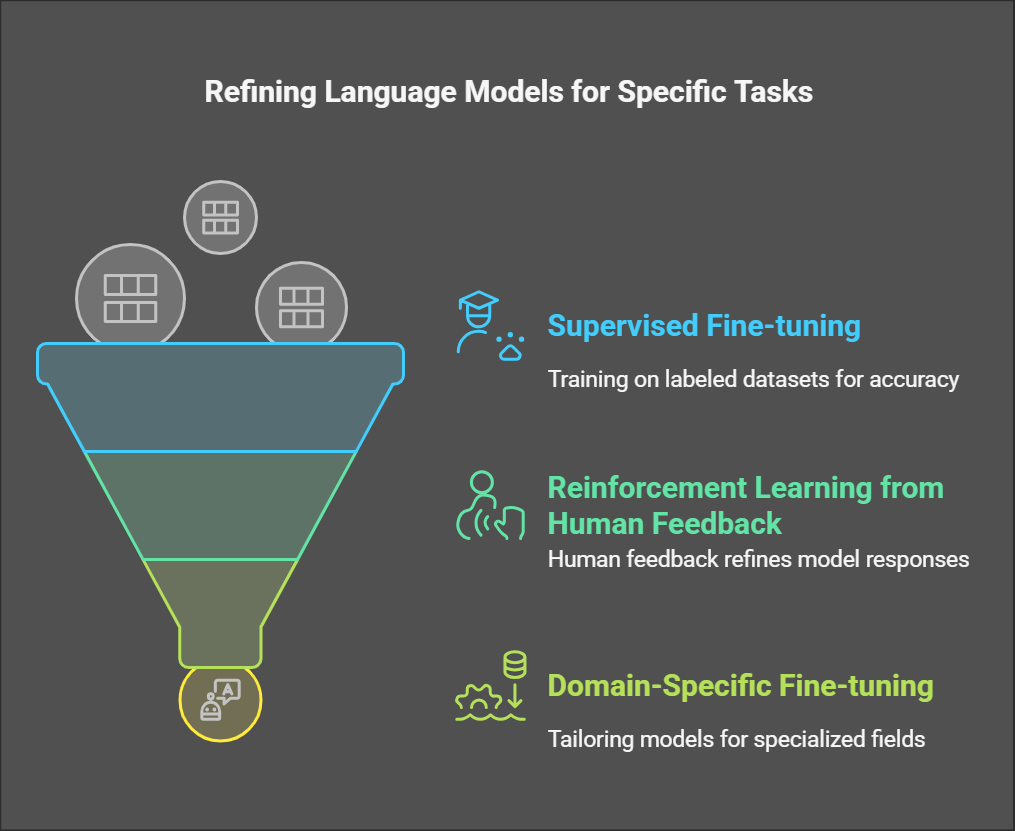
There are different types of fine-tuning:
- Supervised Fine-tuning: The model is trained on labelled datasets where human experts provide correct responses. This helps improve accuracy for specific tasks like summarization, translation, or coding assistance.
- Reinforcement Learning from Human Feedback (RLHF): A more advanced method where human testers rank model outputs, and the system learns to prefer higher-quality responses. This technique was crucial in making models like ChatGPT more user-friendly and aligned with ethical guidelines.
- Domain-Specific Fine-tuning: LLMs can be tailored for specialized fields such as legal, medical, or financial domains by training them on relevant industry data.
3. Inference: Real-World Deployment
After fine-tuning, the model is ready for real-world use. This phase involves:
- Processing user inputs: The model generates dynamic responses based on prompts.
- Context retention: Modern LLMs can remember and reference earlier parts of a conversation.
- Optimization for efficiency: Since running large models requires immense computational power, developers use techniques like model distillation or caching to make inference faster and more cost-effective.
At this stage, the LLM powers applications such as chatbots, code assistants, search engines, content generators, and more—continuously improving based on real-world interactions and feedback.
If this article provided you with value, please support me by buying me a coffee—only if you can afford it. Thank you!
